Token Analysis
词法分析
写在前面
本人选的语言是Java,阅读和借鉴的源码是Javac的源码。选择Java的原因主要是22春的OOP课程用的比较多,比起C++来熟悉不少。最后选择Javac源码来阅读并借鉴主要原因有以下两点:
Javac源码自然是用Java语言书写的,那么在类的设计和使用等方面本身就有很多值得学习和借鉴的地方,之后在借鉴到的地方都会有所提及。Java语言的语法和C的语法有许多共通之处,比如变量类型需要申明,分支、循环语句的小括号和语句块的大括号,语句结尾需要分号等等。
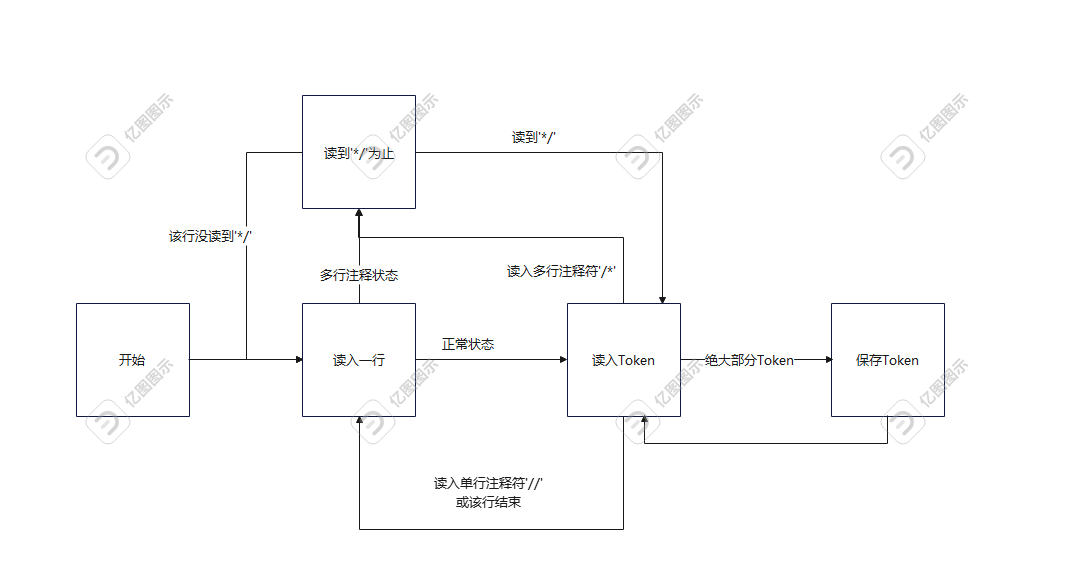
词法分析中我是按行读入的,可能比较少见,我把个人感觉到的按行读入的优缺点分析如下,仅供参考:
- 优点:
- 不需要处理换行符,也不需要考虑不同操作系统上换行符的变化带来的困扰,这也是我选择按行读入的主要原因。
- 对于单行注释符,读到以后可以直接读下一行,不需要持续读到换行符为止。
- 对于行数的记录一定不会出错。
- 缺点:
- 每一行都需要判断是否读完。
- 在多行注释状态下,既需要判断是否读到
*/,还需要判断该行是否结束,较为繁琐。
不过缺点并不是致命的,都可以通过设计进行优化。
其实就是当文档写的,希望之后重构得少一些。
类的设计
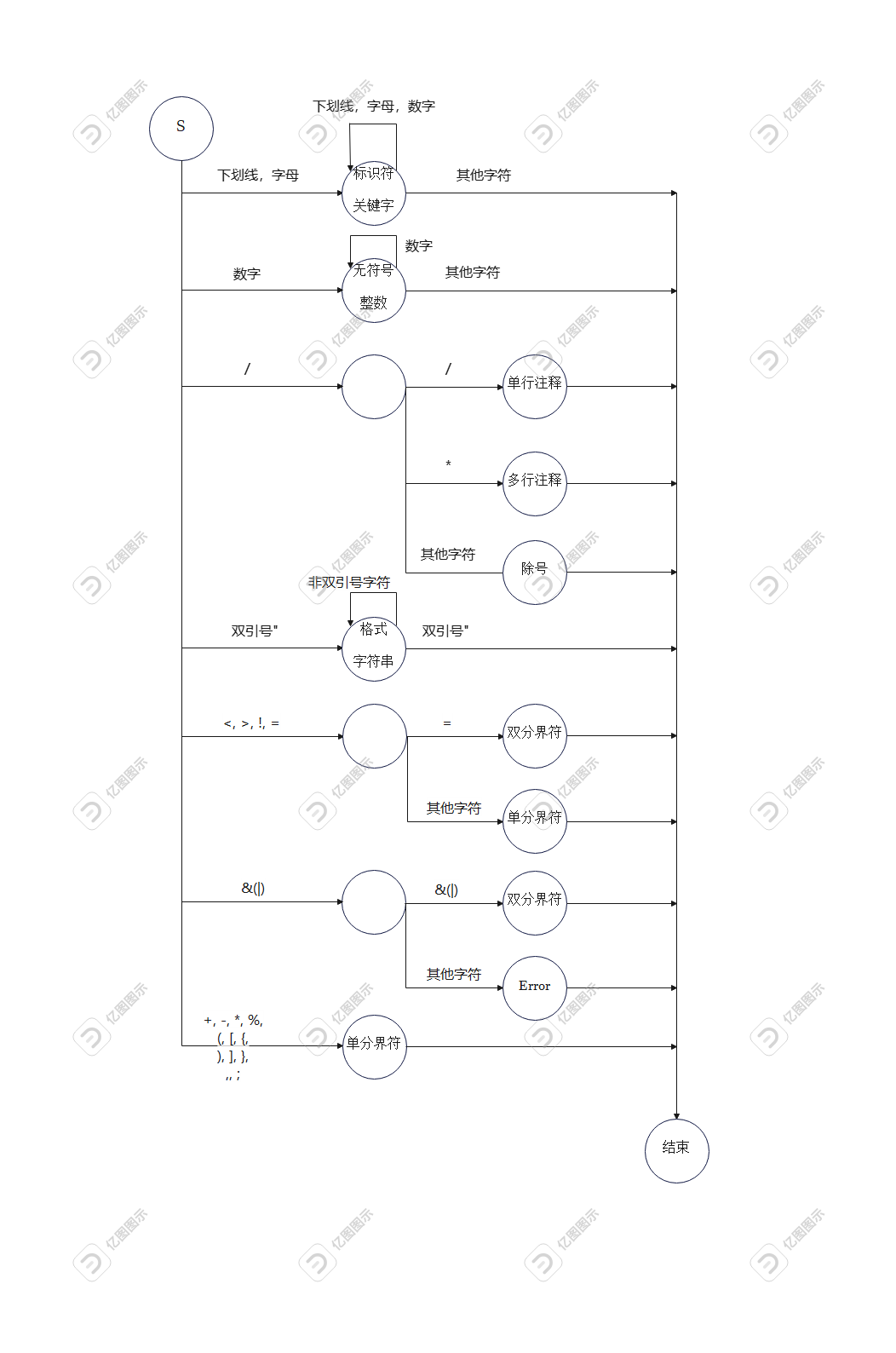
Tokens
- 主要作用:外部类,封装了关于
Token的所有信息及方法。 - 静态成员属性:
HashMap<String, TokenKind> keywords:建立Token名字与Tokenkind之间的对应关系,主要便于之后查找一个Token是否为关键字。
1 | |
- 成员内部类:
TokenKindToken
- 成员方法:
TokenKind lookupKeywords(String name):根据Token名字返回其TokenKind,主要用于识别Token是否为关键字。
TokenKind
- 主要作用:枚举类,记录所有种类的
Token及其类别码。 - 成员属性:
String name:对于关键字和操作符,我赋值为对应的字符串;对于常数,标识符和格式字符串三类,这里的名字比较随意。其实这个属性也可以不需要,主要是为了建立keywords这个对应关系。String code:实验要求输出的类别码。
- 举几个简单的例子:
1 | |
Token
- 主要作用:记录
Token的名字,种类,所在行数,值等信息。 - 成员属性:
TokenKind tokenKindint line:记录所在行数。String value:记录常数,标识符和格式字符串的值(统一用String是偷懒了,对于常数可以在用的时候再转一下)。
这里增加一个
value是因为枚举类无法实例化对象,想在枚举类里枚举所有的常数,标识符和字符串显然不现实,所以在这里记录。
Reader
- 主要作用:阅读文章,记录当前字符和标识符内容。
- 成员属性:
char ch:当前字符。char[] buf:当前缓冲区。int bp:下一个需要读入的字符。int len:缓冲区长度。char[] sbuf:用来保存Token内容的字符数组。int sp:sbuf的下标。String filename:记录读入的文件名。BufferedReader br:用来读入文件内容。
- 成员方法:
boolean readNextLine():读入下一行文件内容。boolean readChar():读入下一个字符。void putChar():将当前字符保存进字符数组。String savedToken():返回当前字符数组里保存的Token内容。boolean is*():判断当前字符的种类,如isPlus(), isStar()等。
Writer
- 主要作用:保存并按格式输出
Token。 - 成员属性:
List<Token> tokens:记录该文件所有读入的Token。String filename:记录输出的文件名。BufferedWriter bw:用来输出文件内容。
- 成员方法:
void saveToken(Token token):保存一个Token。void writeToken():按格式输出所有的Token。
Tokenizer
- 主要作用:每次读入一个
Token并返回。 - 成员方法:
Token readToken():每次读入一个Token并返回。
Compiler
- 主要作用:主编译器,调用所有类和方法完成编译过程。
状态图