Syntax Analysis
语法分析
类的设计
SysYTree
- 主要作用:构建抽象语法树
- 内部类及关系如下图(强迫症为了布局看起来清楚已经花光了所有的精力,后面已经懒得写各个类的属性了):
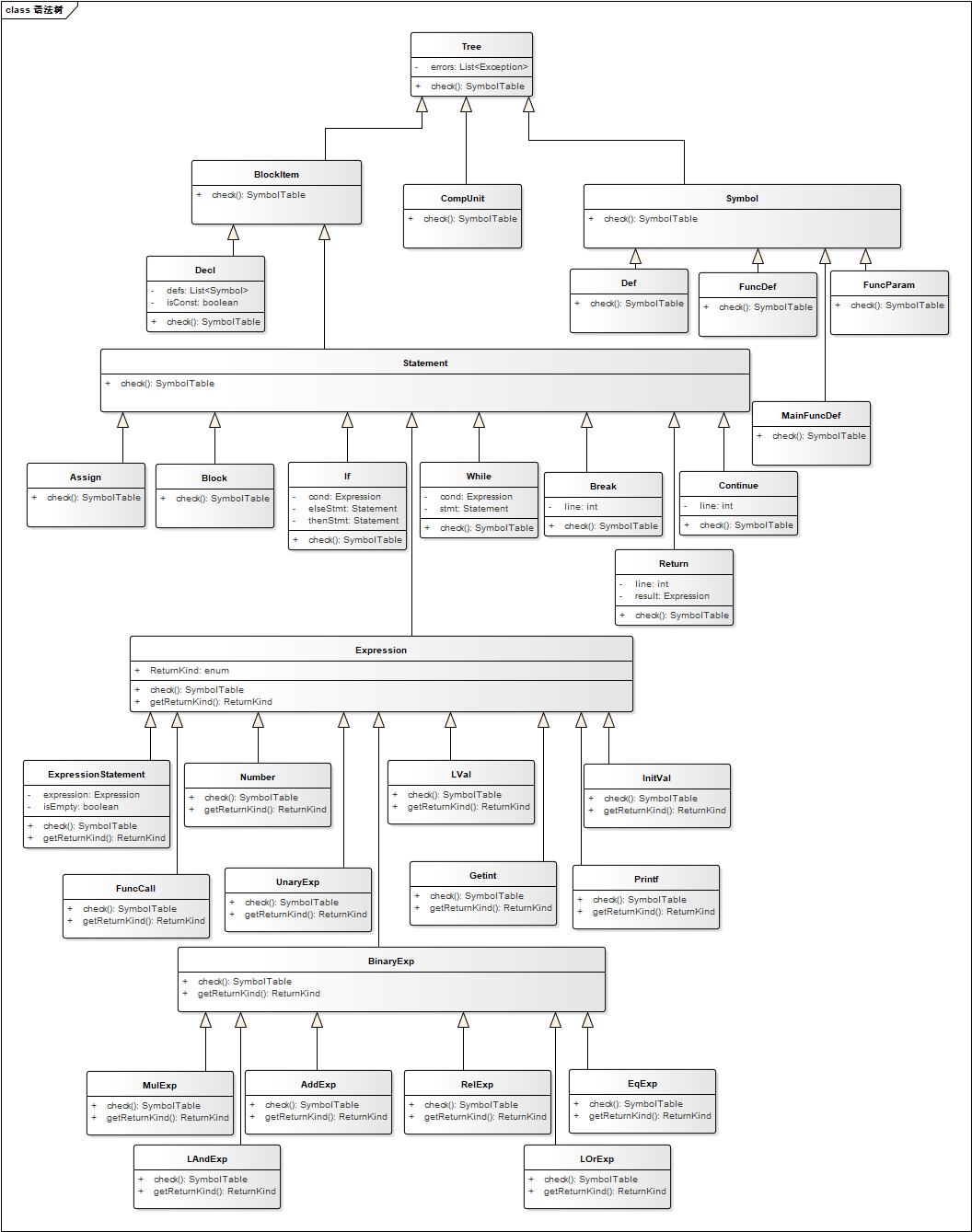
- 这张图是最后完成了符号表构建和错误处理之后的终图,因此有些类是为了这两部分而设计。
- 每个结点包含必要的信息,举几个例子:
1 | |
Scanner
- 主要作用:在词法分析过程中保存
Token,并在语法分析过程中提供Token。 - 成员属性:
ArrayList<Token> tokens:词法分析过程中所有读入的Token。Token token:当前token,通过nextToken设置。
- 成员方法:
void saveToken(Token token):保存一个Token。void nextToken():读取下一个Token。Token getToken():获得当前Token。Token lookAhead(int pos):超前扫描Token。
Writer
- 主要作用:按格式输出语法成分。
- 成员属性:
List<Token> tokens:记录该文件所有读入的Token。String filename:记录输出的文件名。BufferedWriter bw:用来输出文件内容。
- 成员方法:
void write(String out):将对应的语法成分输出到文件中。
Parser
- 主要作用:语法分析器
- 成员方法:
syntaxAnalyse:进行语法分析,并返回顶端树节点CompUnit。- 针对每一个非终结符,编写一个对应的
parse方法,并返回树节点:public SysYCompUnit parseCompilationUnit();public SysYStatement parseStatement();- …
Compiler
- 主要作用:主编译器,调用所有类和方法完成编译过程。
递归下降分析
在Parser类中针对每个非终结符编写一个方法,用递归下降分析法,并在语法分析过程中构建抽象语法树。
个人设计过程中遇到的主要难点及注意事项:
-
语法树的设计,类的继承和多态确实花了很多时间,在参考了
Javac的设计和叶学长的设计后,最终确定了开篇所示的语法树结构。 -
对于变量初值
InitVal → Exp | '{' [ InitVal { ',' InitVal } ] '}':- 在读取到
'{'后可以判断下一个是不是'}'来确定是否要递归读取InitVal; - 对于重复出现的
InitVal,可以用','作为循环判断的条件,对于类似的函数参数、变量定义也是一样,不建议使用';'作为分界符,因为错误处理时可能没有';'。
- 在读取到
-
区分函数定义和变量定义:
- 读到
void时,是函数定义; - 读到
const时,是常量定义; - 读到
int后,采用超前扫描判断标识符ident及其之后的符号:- 如果
ident为main,是主函数定义; - 如果是左小括号,是函数定义;
- 如果是赋值号,是变量定义。
- 如果
- 读到
-
区分
Stmt语法成分的多种选择:- 读到左大括号,是
block; - 读到
if, while, break, continue, return, printf,可以分别处理; - 除此之外,有两种不同的方式区别赋值语句和单独的表达式:
- 用
try...catch先尝试按赋值语句读取:- 在读取
LVal成分后读到了'=',则读取正确,之后读取getint()或Exp; - 否则,读取
[Exp];; - 这种方式比较稳定,但是需要采取回溯的策略,具体如何回溯要根据自己读取
token的方式;或者克隆一个scanner用来试错也是可行的。
- 在读取
- 采用超前扫描,在记录读到下一个
';'前是否读到过'=':- 若读到则为赋值语句,反之为表达式;
- 这种方式在错误处理时,如果该句结尾没有
';',可能会导致意想不到的结果;但是执行起来较为简单,超前扫描也不需要回溯。
- 用
- 读到左大括号,是
-
可以适当记录行号,之后错误处理会用到。
-
需要考虑好各个
parse方法之间的关系,不要忘记在适当的时候读取下一个token。